
Service Worker Basics and Lifecycle
What is a service worker, and how does it function within a Progressive Web App (PWA)?
A service worker is a JavaScript file that runs in the background of a web application, separate from the main web page. It acts as a programmable proxy between the web application, the network, and the browser cache. Service workers enable the creation of Progressive Web Apps (PWAs) by providing offline capabilities, background synchronization, and push notifications. They essentially allow PWAs to function even when the user is offline or has a poor network connection.
Service workers intercept network requests made by the web application and can respond with cached resources, making it possible for the PWA to load quickly and provide a seamless user experience. They also enable background processes, such as syncing data with a server or updating cached resources, without requiring the user to actively interact with the application.
How do you register a service worker for your PWA?
To register a service worker for your Progressive Web App, you need to follow these steps:
- Create a Service Worker File: Write a JavaScript file (e.g., service-worker.js) that will serve as your service worker. This file contains the logic for intercepting network requests and handling background tasks.
- Register the Service Worker: In your main web application file (such as index.html), add the following code snippet inside a JavaScript file:
if (‘serviceWorker’ in navigator) {
navigator.serviceWorker.register(‘/path/to/service-worker.js’)
.then(registration => {
console.log(‘Service Worker registered with scope:’, registration.scope);
})
.catch(error => {
console.error(‘Service Worker registration failed:’, error);
});
}
- Specify the Service Worker Scope: The scope parameter of the register function determines which URLs the service worker will control. It is usually set based on the directory where the service worker file is located. For example, if your service worker file is in the root directory, the scope is ‘/’.
What are the events involved in the service worker lifecycle (installation, activation, update)?
The service worker lifecycle consists of three main events:
- Installation: This event occurs when a new service worker is being installed for the first time. During installation, the service worker file is downloaded, and the browser adds it to the list of available service workers.
- Activation: After the service worker is installed, it enters the activation phase. Here, the browser activates the new service worker and starts managing network requests and caching. The activation event is an opportunity to clean up any old caches from previous versions of the service worker.
- Update: When a new version of the service worker is available (the service worker file has changed), the browser detects the update. The new version runs in the background, but it doesn’t control pages until the current clients (browser tabs) are closed. This ensures that the user experiences consistent behavior during their session.
What are the scopes of a service worker, and how do they impact its functionality?
A service worker’s scope determines the range of URLs that it has control over. It’s defined during registration and impacts how the service worker behaves:
- Scope Definition: When registering a service worker, you specify its scope. For example, if the scope is set to /app/, the service worker will only control URLs under that path.
- Impact on Functionality: The service worker can only control and intercept requests made to URLs that fall within its defined scope. Requests to resources outside the scope won’t be managed by the service worker.
- Importance of Scope: Choosing the correct scope is crucial. Too narrow a scope might prevent the service worker from intercepting important requests, while too broad a scope might lead to unnecessary processing and control over unrelated resources.
How can you ensure reliable registration of a service worker for advanced techniques?
Ensuring reliable service worker registration is vital for implementing advanced techniques in a Progressive Web App. Here are some steps to ensure a dependable registration process:
- Include a Versioning Strategy: Maintain a clear versioning strategy for your service worker file. When making changes, increment the version number in the file. This helps ensure that the browser considers the new service worker as an update.
- Implement Update Handling: Inside the service worker, include logic to handle updates. When a new service worker is detected, use the activate event to manage resources from the previous version, such as cleaning up old caches.
- Test Across Browsers: Test service worker registration and updates across different browsers to ensure consistent behavior. Some browsers might have variations in their service worker implementation.
- Use HTTPS: Service workers are only available on secure origins (sites using HTTPS). Ensure that your site is served over HTTPS to allow service worker registration.
- Check Browser Support: Confirm that the browsers you’re targeting support the required service worker features. Some older browsers might have limited or no support for certain advanced techniques.
- Graceful Degradation: If a service worker fails to register or activate, ensure that your PWA gracefully falls back to a default behavior that doesn’t rely on advanced techniques, maintaining a functional user experience.
By following these steps, you can enhance the reliability of service worker registration and updates, enabling the successful implementation of advanced techniques within your Progressive Web App.
Background Sync and Offline Functionality

What is background sync, and why is it crucial for maintaining offline functionality?
Background sync is a feature that allows a web application, specifically a Progressive Web App (PWA), to schedule and perform data synchronization tasks with a remote server in the background, even when the application isn’t actively open or the device is offline. This means that data updates, user interactions, or any other relevant changes made while offline can be synchronized and updated on the server once a network connection is restored.
Background sync is crucial for maintaining offline functionality because it ensures that the user’s interactions are not lost due to network disruptions. It provides a seamless user experience by enabling the application to “catch up” with the server when connectivity is available again. This is especially important in scenarios where users might be in areas with intermittent or poor network coverage, such as on public transport or in remote locations.
Can you explain the APIs and browser compatibility associated with background sync?
The Background Sync API is used to implement background synchronization in PWAs. It involves two main components:
- ServiceWorkerRegistration API: This API allows the service worker to register a background sync task. The method registerSync is used to define the task’s name and options. This API is supported in modern browsers, including Chrome, Firefox, Edge, and Safari.
- Sync Event: Once a background sync task is registered, the service worker listens for the sync event. When triggered, the service worker can perform the desired synchronization logic. This event is fired when the network connection is available and the browser decides it’s an appropriate time to sync.
Browser compatibility for the Background Sync API is widespread among major modern browsers. However, it’s essential to check the specific versions and documentation for any updates or variations.
What strategies can you use to implement delayed synchronization and handle varying network states?
Implementing delayed synchronization and handling varying network states requires careful consideration of user experience and data integrity. Here are strategies to achieve this:
- Queueing Mechanism: Maintain a queue of synchronization tasks within the service worker. When the network is unavailable, tasks are queued and executed when the network is restored.
- Exponential Backoff: Implement an exponential backoff strategy for retrying failed synchronization tasks. If a task fails due to a network error, delay subsequent retries for increasing intervals to avoid overwhelming the network.
- Throttling: Implement throttling to control the frequency of synchronization attempts. Throttle the synchronization process to avoid excessive battery consumption and network congestion.
- User Control: Provide users with the option to trigger manual synchronization when they have a reliable network connection. This can be especially useful in scenarios where users want to ensure their data is up to date before going offline.
- Data Bundling: Bundle multiple synchronization tasks into a single request. This reduces the number of network requests and can optimize the synchronization process.
How can you integrate background sync with the user interface to enhance the user experience?
Integrating background sync with the user interface (UI) can significantly enhance the user experience by providing transparency and control over synchronization activities. Here’s how to achieve this integration:
- Visual Indicators: Display a visual indicator, such as an icon or progress bar, when synchronization is in progress. This informs users that their data is being synchronized in the background.
- Sync Status Messages: Provide status messages or tooltips that inform users about the ongoing synchronization process. Messages like “Data syncing…” or “Your changes are being saved” offer reassurance.
- Sync History: Create a sync history log that users can access. This log displays the status and timestamps of previous synchronization activities, giving users a sense of control and visibility.
- Manual Sync Trigger: Include a manual synchronization trigger in the user interface. This empowers users to initiate synchronization on-demand when they want to ensure their data is up to date.
- Offline Mode Feedback: When the device is offline, notify users about the pending synchronization tasks. Inform them that changes will be synchronized once a network connection is available.
What methods can you employ to provide user feedback during background sync processes?
Providing user feedback during background sync processes is crucial for transparency and user confidence. Here are methods to offer effective feedback:
- Progress Indicators: Use progress indicators, such as progress bars or animated icons, to visually represent the synchronization progress. Users can see that the app is actively working in the background.
- Status Messages: Display clear status messages near the sync trigger or relevant sections of the app. Messages like “Sync in progress” or “Data updating” give users immediate feedback.
- Notification Badges: Add a badge or notification count to the app’s icon, indicating that background sync is ongoing. This provides a glanceable way for users to know that updates are being processed.
- Real-time Updates: For tasks that are being synchronized in real-time, such as chat messages, display updates as they’re synced. This gives users a sense of the dynamic nature of the sync process.
- Success and Failure Alerts: Show success alerts when synchronization is completed and failed alerts if there were issues. These alerts help users understand the outcome of the sync.
By employing these methods, you can keep users informed about ongoing background sync processes, ensuring they are aware of the app’s activity and maintaining a positive user experience.
Push Notifications and Real-time Communication
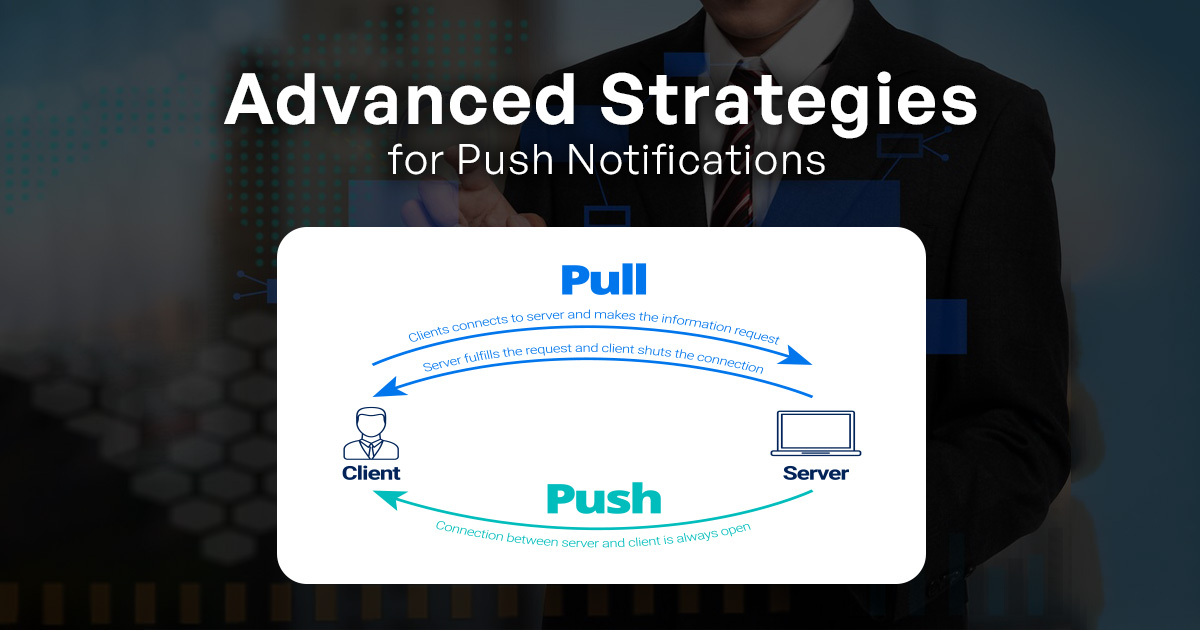
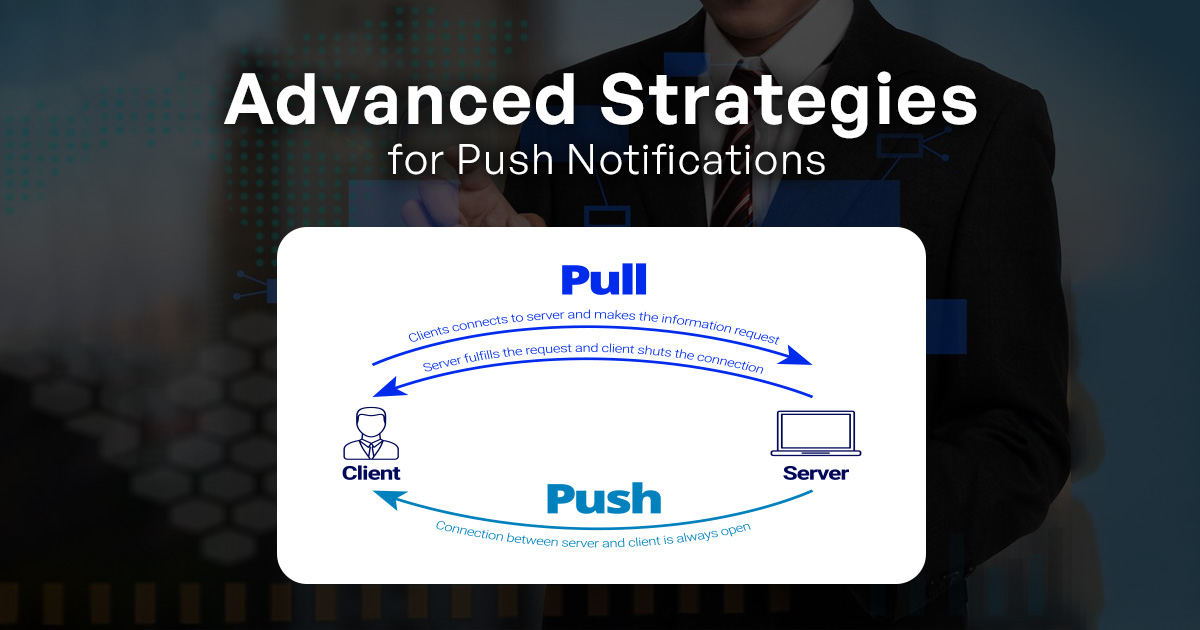
What is the mechanism behind push notifications in PWAs, and why are they significant?
Push notifications in PWAs rely on the Push API and the underlying service worker to deliver real-time updates and alerts to users. The mechanism involves several steps:
- User Subscription: When a user opts to receive push notifications, the service worker subscribes to a push service (e.g., Firebase Cloud Messaging, Apple Push Notification Service) on behalf of the user.
- Push Server Interaction: The push service generates a unique endpoint URL for the user’s device. This endpoint is used by the server to send notifications.
- Notification Request: The server sends a notification request to the push service endpoint with the notification content.
- Service Worker Handling: The service worker receives the push event, and if the app isn’t open, it’s woken up to handle the event. The service worker can then display the notification to the user or perform custom logic.
Push notifications are significant because they enable timely and personalized communication with users, even when the app is not actively open. They engage users, provide important updates, and encourage re-engagement with the app, enhancing user retention and interaction.
How do you implement payload encryption and decryption for secure push notifications?
To implement payload encryption and decryption for secure push notifications, follow these steps:
- Payload Encryption:
- Encrypt the notification content using a secure encryption algorithm (e.g., AES) on the server-side.
- Generate a unique encryption key for each notification or recipient.
- Include the encrypted content and necessary metadata (e.g., keys, initialization vectors) in the notification payload.
- Service Worker Decryption:
- Inside the service worker, intercept the push event.
- Decrypt the encrypted payload using the appropriate decryption algorithm and the decryption key.
- Extract the decrypted content and use it to customize the notification.
By implementing encryption and decryption, you ensure that notification content remains confidential and secure during transmission and while stored on the user’s device.
What are silent push notifications, and how can they be used to optimize message delivery?
Silent push notifications are push notifications that don’t display a visible message to the user but instead trigger actions in the background. They can be used to optimize message delivery by updating app data, fetching new content, or performing tasks without interrupting the user experience.
Uses of silent push notifications for optimization include:
- Data Synchronization: Trigger synchronization with the server to keep data up to date.
- Content Pre-fetching: Fetch content in advance, so it’s ready when the user interacts with the app.
- Background Tasks: Perform maintenance or processing tasks behind the scenes.
Silent push notifications are valuable because they allow apps to stay up to date without causing user distractions or requiring their interaction. This is particularly useful for maintaining a seamless and responsive user experience.
Can you compare WebSockets and push notifications for real-time communication in PWAs?
WebSockets:
- WebSockets provide a full-duplex communication channel between the client (browser) and the server.
- They are suited for scenarios requiring continuous, bidirectional communication, such as chat applications.
- WebSockets are initiated by the client, establishing a direct connection to the server.
- They involve lower latency compared to traditional HTTP requests, making them suitable for real-time interactions.
Push Notifications:
- Push notifications involve one-way communication from the server to the client (browser).
- They are suited for delivering updates, alerts, and notifications to users even when the app is not open.
- Push notifications are initiated by the server and can be triggered based on events or schedules.
- They are more suitable for scenarios where real-time interaction is not required, and the server initiates communication.
In summary, WebSockets are better for continuous, bidirectional communication, while push notifications are effective for one-way communication, delivering updates and alerts to users.
How do you establish persistent connections and minimize latency with push notifications?
To establish persistent connections and minimize latency with push notifications, follow these guidelines:
- Service Worker Registration: Ensure that your service worker is registered to handle push events. This establishes the foundation for receiving push notifications.
- Use Push Service: Choose a reliable push service provider (e.g., Firebase Cloud Messaging, Apple Push Notification Service) to manage the push infrastructure. These services handle connection management, delivery, and retries.
- Efficient Payloads: Optimize notification payloads for minimal data usage. Keep the payload concise and relevant to reduce the time needed for transmission.
- Custom Notification Handling: Implement custom logic inside the service worker to handle push events efficiently. For silent notifications, perform background tasks without disrupting the user.
- Connection Keep-Alive: Push services often utilize a long-lived connection. This minimizes the overhead of repeatedly establishing connections for each notification.
- Content Delivery Networks (CDNs): Use CDNs to serve resources, such as images or icons, required for notifications. This reduces the latency associated with retrieving notification content.
- Quality of Service (QoS): Choose a push service provider that offers QoS features, such as delivery guarantees and retries, to ensure reliable notification delivery.
Data Pre-caching and Compression
What are predictive and proactive data pre-caching techniques, and how do they work?
Predictive Data Pre-caching: Predictive pre-caching involves analyzing user behavior and historical usage patterns to anticipate what content a user might need in the future. Based on this analysis, the PWA pre-caches relevant resources in advance. For example, if a user frequently visits a news section at a specific time, the PWA can pre-fetch those news articles before the user’s typical visit time.
Proactive Data Pre-caching: Proactive pre-caching goes a step further by anticipating the user’s needs even before they explicitly show a pattern. It leverages AI or machine learning algorithms to predict what content a user might find valuable based on broader trends and user preferences. This technique is more advanced and requires access to substantial historical data.
Both techniques involve intelligent analysis and prediction of user behavior to optimize the pre-caching of resources, enhancing the user experience by ensuring that desired content is readily available.
How can adaptive algorithms be employed to efficiently pre-cache data?
Adaptive algorithms can enhance the efficiency of data pre-caching by dynamically adjusting pre-caching strategies based on changing conditions. Here’s how to employ them:
- Dynamic Thresholds: Set adaptive thresholds for pre-caching based on factors like network speed, device type, and user behavior. For slower networks, pre-cache fewer resources to prevent overloading the network.
- Machine Learning: Utilize machine learning to continuously learn from user interactions and optimize pre-caching based on real-time data.
- Contextual Analysis: Analyze contextual information, such as location, time of day, and user preferences, to determine which resources are most likely to be needed.
- Feedback Loop: Establish a feedback loop that evaluates the effectiveness of pre-caching. If a pre-cached resource is frequently accessed, the algorithm can prioritize similar resources in the future.
- Dynamic Updating: Periodically update the adaptive algorithm with new data and insights to ensure that it remains accurate and aligned with changing user behavior.
By implementing adaptive algorithms, you can tailor data pre-caching to the specific needs and behaviors of your users, optimizing resource utilization and enhancing user experience.
What strategies are available for prefetching critical resources based on user behavior?
Prefetching critical resources based on user behavior involves anticipating which resources users are likely to access and pre-fetching them. Here are strategies to achieve this:
- Page Predictions: Analyze the user’s navigation history and predict the next likely page they’ll visit. Pre-fetch resources related to that page.
- Hover Previews: Prefetch resources associated with links that the user hovers over, assuming they might click on those links.
- Predictive Analytics: Employ predictive analytics to anticipate which resources a user is likely to need based on historical data and usage patterns.
- Contextual Triggers: Trigger pre-fetching based on contextual cues like location, time of day, or device type. For example, pre-fetch restaurant reviews when the user’s location indicates they might be looking for dining options.
- Real-time Interactions: Pre-fetch resources related to actions a user is currently taking, such as pre-fetching search results as they type in a search bar.
By implementing these strategies, you can reduce load times and provide a seamless user experience by ensuring that critical resources are readily available.
How can data compression algorithms be balanced for optimal performance during background transfers?
Balancing data compression algorithms for optimal performance during background transfers involves considering factors like compression ratio, processing speed, and the nature of the data. Here’s how to achieve this balance:
- Algorithm Selection: Choose compression algorithms based on the type of data being transferred. For text-based data, algorithms like GZIP or Brotli are effective. For images or multimedia, consider image-specific compression formats like WebP.
- Compression Level: Many compression algorithms offer different levels of compression. Higher compression levels yield smaller file sizes but might be slower to process. Adjust the compression level based on the urgency of the transfer.
- Resource Size: Smaller resources might not benefit significantly from compression, so consider skipping compression for very small files.
- Dynamic Compression: Implement dynamic compression detection. If a resource is already highly compressed (e.g., images in WebP format), don’t attempt further compression, as it can increase processing time without substantial gains.
- Testing and Benchmarking: Test different compression algorithms and levels on representative data samples to determine which combinations offer the best trade-off between compression and performance.
By finding the right balance between compression efficiency and processing speed, you can ensure optimal performance during background data transfers.
What types of data are best suited for efficient compression in background tasks?
Efficient compression is particularly effective for certain types of data that exhibit redundancy or patterns suitable for reduction. These include:
- Textual Data: Plain text, HTML, CSS, and JavaScript files often contain repetitive characters and structures that can be significantly compressed.
- JSON and XML: Data interchange formats like JSON and XML benefit from compression due to their verbose nature and repetitive key-value pair structures.
- Structured Data: Structured data, such as databases or spreadsheets, can be compressed effectively, especially if they contain a large amount of repeated data.
- Image and Multimedia Data: Images, audio, and video files can also be compressed using specialized algorithms such as lossless WebP or lossy JPEG for images.
- Web Fonts: Font files, especially those with variable fonts, can be compressed to reduce loading times.
- Resource Bundles: Bundling multiple resources together and compressing them as a package can reduce overhead associated with individual file compression.
Keep in mind that not all types of data benefit equally from compression. Carefully consider the nature of the data and the compression algorithm’s effectiveness to determine if compression is suitable and beneficial for your background tasks.
Data Storage and Synchronization
What role does IndexedDB play in offline data storage for PWAs?
IndexedDB is a low-level, client-side storage API that allows PWAs to store significant amounts of structured data locally, providing offline data storage capabilities. It’s particularly useful for storing data that the PWA needs to function even when the user is not connected to the internet.
IndexedDB provides a way to create, read, update, and delete data records, and it offers a powerful querying mechanism for retrieving data efficiently. PWAs can use IndexedDB to cache resources, store user-generated data, and manage local copies of data from remote servers.
How do you structure data within IndexedDB, and what is the process for managing transactions?
Structuring data within IndexedDB involves defining an object store that acts as a container for your data. Here’s a basic process:
- Database Creation: Open or create an IndexedDB database.
- Object Store Creation: Create one or more object stores within the database. Each object store represents a collection of data.
- Data Addition: Add data to object stores using the add or put methods.
- Data Retrieval: Retrieve data using indexes or keys with the get method or more complex queries.
- Data Updates and Deletion: Update or delete data using the put or delete methods.
Transactions are essential for ensuring data consistency and integrity. The process involves:
- Transaction Creation: For read or write operations, create a transaction on the desired object store.
- Perform Operations: Within the transaction, perform your read or write operations.
- Transaction Completion: Once the operations are complete, finalize the transaction. If any operation fails, the entire transaction is rolled back, ensuring data integrity.
What are cache storage API naming conventions, and how do they impact cached data?
Cache storage API naming conventions involve associating a name with a cache. When resources are fetched and stored in the cache, they are identified by the cache’s name. Naming conventions impact cached data in the following ways:
- Resource Separation: By naming caches based on their purpose (e.g., ‘images-cache’, ‘api-cache’), you can separate different types of resources and manage them independently.
- Versioning: Including version information in cache names (e.g., ‘images-cache-v1’, ‘images-cache-v2’) allows you to manage cache updates and migrations gracefully.
- Cache Management: Naming conventions facilitate cache management, as you can easily identify and manipulate specific caches when needed.
- Cache Invalidation: By changing the cache name during updates, old caches with outdated resources can be discarded, promoting cache invalidation.
What strategies can you use for cache invalidation, updates, and managing cached data?
Cache invalidation, updates, and data management in the cache involve careful planning to ensure users receive the latest resources. Strategies include:
- Cache Invalidation: Periodically check for updates on the server. When new versions of resources are available, delete old caches and replace them with updated content.
- Service Worker Versioning: When updating a service worker, change its version to trigger cache updates. You can then remove old caches during the service worker activation phase.
- Cache Expiry: Set expiration times for cached resources. If a resource is too old, fetch a fresh version from the server.
- Offline-First Fetching: Before fetching from the network, check the cache. If the cached resource is available, use it; otherwise, fetch from the network and update the cache.
- Cache Size Management: Monitor cache size and use cache pruning strategies to remove least-used or least-recently accessed resources.
How are offline data synchronization modes and frequency determined?
Offline data synchronization modes and frequency depend on various factors related to the PWA’s functionality and user experience. Consider these factors:
- App Requirements: Determine what data needs to be synchronized. Is it essential for the app’s core functionality, or can it wait for network connectivity?
- User Expectations: Consider user expectations. If the app provides real-time updates (e.g., messaging app), prioritize more frequent synchronization.
- Network Conditions: Optimize synchronization frequency based on network conditions. Frequent synchronization on slow or unreliable networks might impact user experience negatively.
- Battery Consumption: Frequent synchronization can drain the device’s battery. Balance synchronization frequency to avoid excessive energy consumption.
- Data Volume: If the amount of data to synchronize is large, consider batching or compressing data to reduce the impact on user data plans.
- Conflict Handling: If multiple users can modify the same data, consider conflict resolution mechanisms. Frequent synchronization might lead to more conflicts.
By analyzing these factors, you can determine the most suitable offline data synchronization modes and frequency for your PWA, providing a balance between user experience and resource utilization.
Security and Encryption
How is end-to-end encryption implemented for push notifications in PWAs?
End-to-end encryption for push notifications ensures that only the intended recipient can decrypt and read the notification’s content. Here’s how it’s implemented:
- Client-Side Encryption:
- When the PWA registers for push notifications, a unique public-private key pair is generated on the client side.
- The public key is sent to the push service during subscription.
- The private key remains securely on the client device and is never shared.
- Server-Side Encryption:
- When a server wants to send a push notification, it uses the recipient’s public key to encrypt the notification payload.
- The encrypted payload is sent to the push service along with the recipient’s subscription information.
- Client Decryption:
- When the push service receives the encrypted payload, it sends it to the recipient device.
- The recipient’s PWA uses its private key to decrypt the payload and display the notification’s content.
End-to-end encryption ensures that even if the push service or other intermediaries are compromised, the notification content remains unreadable without the recipient’s private key.
What are the considerations for managing certificates and ensuring privacy?
Managing certificates and ensuring privacy involves several considerations:
- Certificate Authority (CA): Obtain SSL/TLS certificates from reputable CAs to ensure encrypted communication between the PWA and the server. Regularly renew certificates to prevent expiration.
- Certificate Storage: Store certificates securely, avoiding exposure to unauthorized parties. Use secure key stores and follow best practices for certificate management.
- Certificate Revocation: Implement mechanisms to revoke compromised or outdated certificates promptly. This prevents unauthorized access.
- HTTPS: Use HTTPS to encrypt data transmission between the PWA and the server. Avoid transmitting sensitive data over unencrypted connections.
- Privacy Regulations: Adhere to relevant privacy regulations (e.g., GDPR) when handling user data. Ensure that data is encrypted both in transit and at rest.
How can you ensure secure background data transfer and manage user permissions?
To ensure secure background data transfer and manage user permissions, follow these practices:
- Secure APIs: Use secure protocols (HTTPS) and authentication mechanisms for API calls, even during background tasks. Implement authorization checks to ensure only authorized users access the data.
- Background Sync Permissions: Clearly inform users about background sync and data usage during push notification and background processes. Obtain user consent before enabling background sync.
- User Data Protection: Implement strict data protection measures. Avoid storing sensitive data locally unless necessary, and encrypt data that’s stored.
- Permission Management: Provide users with granular control over permissions related to background processes, push notifications, and data access.
- Minimum Data Collection: Collect only the necessary data for background processes and notifications. Minimize the data that’s sent to and stored on the server.
What measures are taken to maintain security during background processes?
Maintaining security during background processes involves multiple layers of protection:
- Isolation: Use service workers to execute background processes. Service workers are isolated from the main thread and can’t access the DOM directly, reducing attack vectors.
- Origin Policies: Implement same-origin policies to prevent unauthorized access to resources from different origins.
- CSP (Content Security Policy): Utilize CSP to restrict the sources from which scripts and resources can be loaded. This prevents code injection and other attacks.
- Authentication and Authorization: Apply strong authentication and authorization mechanisms to prevent unauthorized users from accessing resources.
- Data Validation: Validate and sanitize input data to prevent injection attacks and ensure data integrity.
- Monitoring and Logging: Implement robust logging and monitoring mechanisms to detect and respond to any abnormal behavior or security breaches.
- Regular Updates: Keep service workers, libraries, and dependencies up to date to address security vulnerabilities promptly.
- Secure Communication: Use encryption (HTTPS) for communication between the PWA, server, and push service. Encrypt data at rest and during transmission.
By implementing these security measures, you can minimize the risks associated with background processes and ensure the integrity and privacy of your PWA and its interactions.
Background Sync Task Management

What are the strategies for throttling and queuing background sync tasks efficiently?
Efficient throttling and queuing of background sync tasks are essential to ensure optimal performance and resource utilization. Consider these strategies:
- Task Priority: Assign priority levels to sync tasks based on their importance. Process high-priority tasks before lower-priority ones.
- Rate Limiting: Limit the frequency of sync requests to prevent overwhelming the server or draining device resources.
- Batching: Group multiple sync tasks together into batches to minimize the overhead of initiating multiple requests.
- Queue Management: Implement a queue system to manage sync tasks. This helps ensure tasks are executed in a controlled order.
- Dependency Management: If some tasks depend on the completion of others, manage the dependencies within the queue.
How can adaptive throttling algorithms and rate limiting strategies be implemented?
Adaptive throttling algorithms and rate limiting strategies adjust the rate of sync tasks based on factors like network conditions and device resources. Here’s how to implement them:
- Network Condition Monitoring: Continuously monitor network conditions, including speed and stability.
- Adaptive Throttling: Increase or decrease the frequency of sync tasks based on the detected network conditions. Throttle more aggressively on slow or unstable networks.
- Rate Limiting: Set an initial sync rate and adjust it dynamically based on the success rate of sync tasks. If many tasks fail, reduce the sync rate temporarily.
- Backoff Mechanism: Implement exponential backoff, where the time between retries increases with each consecutive failure.
- User Preferences: Allow users to customize the sync rate or throttling behavior based on their preferences.
What approaches are effective for handling sync errors and implementing retry/backoff mechanisms?
Handling sync errors and implementing retry/backoff mechanisms improve the reliability of background sync tasks. Effective approaches include:
- Retry Strategy: When a sync task fails, schedule a retry after a brief delay. If the retry is successful, continue; otherwise, increase the delay for subsequent retries.
- Exponential Backoff: Increase the delay between retries exponentially to prevent overloading the server and allowing transient issues to resolve.
- Maximum Retry Count: Set a maximum number of retries. If a task consistently fails, consider notifying the user or taking alternative actions.
- Error Logging: Log sync errors and their details for analysis. This helps identify persistent issues and fine-tune retry strategies.
- User Notification: If sync tasks repeatedly fail, inform the user about the issue and suggest manual intervention.
Can you explain the concept of adaptive throttling in the context of background sync?
Adaptive throttling adjusts the rate of background sync tasks based on changing conditions to optimize resource usage and maintain a reliable user experience. In the context of background sync, adaptive throttling considers factors such as network quality, device resources, and historical sync success rates to determine how frequently sync tasks should occur.
For example, consider a situation where the network connection is unstable or slow. Adaptive throttling might dynamically reduce the frequency of sync tasks to avoid overloading the network and prevent excessive battery consumption. Conversely, on a fast and stable network, adaptive throttling might allow more frequent sync tasks to ensure timely updates.
Adaptive throttling involves continuous monitoring of various parameters, including network speed, signal strength, and the success or failure rates of sync tasks. Algorithms analyze this data to make informed decisions about adjusting the sync rate. This adaptability ensures that background sync tasks are performed optimally under varying conditions, improving the overall performance and efficiency of the application.
Advanced Service Worker Techniques
How can domain-specific requirements influence the implementation of advanced background sync?
Domain-specific requirements play a significant role in shaping the implementation of advanced background sync. Here’s how they can influence the process:
- Data Sensitivity: If your domain involves sensitive data (e.g., medical records), you might need stricter security measures, encryption, and more robust error handling during background sync.
- Real-time Updates: Certain domains, like financial services, require near-real-time updates. This might influence the frequency of sync tasks and the priority of specific data.
- User Expectations: Different domains have varying user expectations for data freshness. E-commerce apps might need frequent inventory updates, while a weather app can have less frequent updates.
- Resource Types: Depending on the domain, you might prioritize syncing specific resource types. For example, a social media app might prioritize image uploads over text posts.
- Conflict Resolution: If users in your domain can modify the same data from multiple devices, conflict resolution mechanisms become crucial.
- Regulatory Compliance: Domains like healthcare or finance often have strict regulations. Compliance might dictate data handling practices during background sync.
- Resource Prioritization: Some domains might require prioritizing certain resources over others based on business rules or user preferences.
Understanding these domain-specific factors ensures that your background sync implementation aligns with the unique needs and expectations of your application’s users and stakeholders.
What are multi-step workflows, and how can they be incorporated into background sync processes?
Multi-step workflows involve a series of connected actions or processes that need to be executed in a specific order. In the context of background sync processes, multi-step workflows allow you to orchestrate complex tasks efficiently. Here’s how they can be incorporated:
- Task Dependencies: Break down complex sync tasks into smaller steps. Each step can depend on the successful completion of the previous one.
- Sequential Execution: Define the order in which steps should be executed. This ensures that each step is completed before moving on to the next one.
- Error Handling: Incorporate error handling mechanisms for each step. If a step fails, you can implement retries, notify users, or initiate alternative actions.
- Logging and Monitoring: Implement detailed logging to track the progress of multi-step workflows. This helps in debugging and understanding the flow of tasks.
- Parallel Execution: In some cases, certain steps can be executed in parallel to improve efficiency. However, ensure that dependencies and data integrity are maintained.
What strategies are employed when building complex background sync processes?
Building complex background sync processes requires careful planning and coordination. Here are strategies to employ:
- Task Segmentation: Divide complex processes into smaller, manageable tasks. Each task should have a well-defined purpose.
- Dependency Management: Identify task dependencies and order them appropriately. Ensure that tasks that rely on the output of others are executed in the correct sequence.
- Error Handling: Implement robust error handling mechanisms. Each task should have a clear strategy for retries, backoff, and notifications in case of failure.
- Transactional Integrity: If a multi-step workflow involves data modifications, ensure transactional integrity. All tasks within a workflow should succeed or fail together.
- Logging and Monitoring: Implement comprehensive logging to track the progress of each task and the overall workflow. This aids in diagnosing issues and understanding task behavior.
- Testing: Thoroughly test complex sync processes in various scenarios, including edge cases and failure scenarios.
- User Communication: If complex tasks involve user data or actions, communicate clearly with users about the progress and outcomes of these processes.
- Adaptability: Design processes to be adaptable to changing conditions, such as network disruptions or resource availability.
Background Sync for Data Manipulation
How can fetch interceptors be used to modify fetch requests in a service worker?
Fetch interceptors allow you to intercept and modify fetch requests made by a service worker. They provide a powerful mechanism for enhancing or altering network requests. Here’s how you can use fetch interceptors:
- Register Interceptors: Within the service worker, use the self.addEventListener(‘fetch’, …) event listener to intercept fetch requests.
- Modify Requests: When a fetch event occurs, access the event.request object. You can clone the request, modify headers, change the URL, or add additional information.
- Return Responses: After modifying the request, you can respond with a modified or entirely new response using event.respondWith(…). This could involve fetching from the network, responding with cached data, or generating a synthetic response.
Fetch interceptors are commonly used to implement caching strategies, manipulate headers, or implement custom routing based on specific criteria.
What are request and response interceptors, and how are they implemented?
Request and response interceptors are similar concepts that involve intercepting network requests and responses, respectively, and allowing you to modify or manipulate them.
- Request Interceptors: These interceptors operate before a fetch request is made. They allow you to modify the request’s URL, headers, or body before it’s sent to the network.
- Response Interceptors: These interceptors operate when a response is received. They enable you to manipulate the response’s content, headers, or status before it’s delivered to the requesting code.
Both types of interceptors are implemented using the fetch event listener in a service worker. For request interception, you modify the event.request object before calling event.respondWith(…). For response interception, you modify the event.response before it’s passed to event.respondWith(…).
How can URLs and headers be rewritten for advanced data manipulation in service workers?
Rewriting URLs and headers in service workers is a powerful technique for advanced data manipulation. Here’s how to achieve this:
- URL Rewriting: Intercept the fetch request and modify the event.request.url property to redirect the request to a different URL. This can be used for routing requests to different resources or versions.
- Header Modification: Access the event.request.headers property to modify headers before sending the request. You can add, remove, or modify headers to control how the request is processed.
- Response Header Manipulation: Intercept the response using the fetch event’s response interceptor. Modify the event.response.headers to alter response headers before delivering the response.
Rewriting URLs and headers is useful for scenarios such as versioned APIs, dynamic routing, request authentication, and more.
Can you provide examples of scenarios where data manipulation via interceptors is beneficial?
- Caching Strategies: Interceptors can implement advanced caching strategies. For example, a service worker could intercept requests and return cached responses, update the cache, and fetch updated content from the network simultaneously.
- Authorization: By intercepting requests, you can add authorization headers based on the user’s authentication state, without modifying the actual requesting code.
- Dynamic Routing: Service workers can route requests to different resources based on specific criteria. For example, based on a user’s location, you could fetch localized content from different endpoints.
- Response Transformation: Intercepting responses allows you to transform data before delivering it to the client. For instance, you could compress responses on-the-fly or convert response formats.
- A/B Testing: Using interceptors, you could route requests to different versions of resources, enabling A/B testing without changing client-side code.
- Offline Enhancements: By intercepting requests and responses, you can implement advanced offline strategies, like returning placeholder content when offline and updating it later.
Service Worker Versioning and Updates
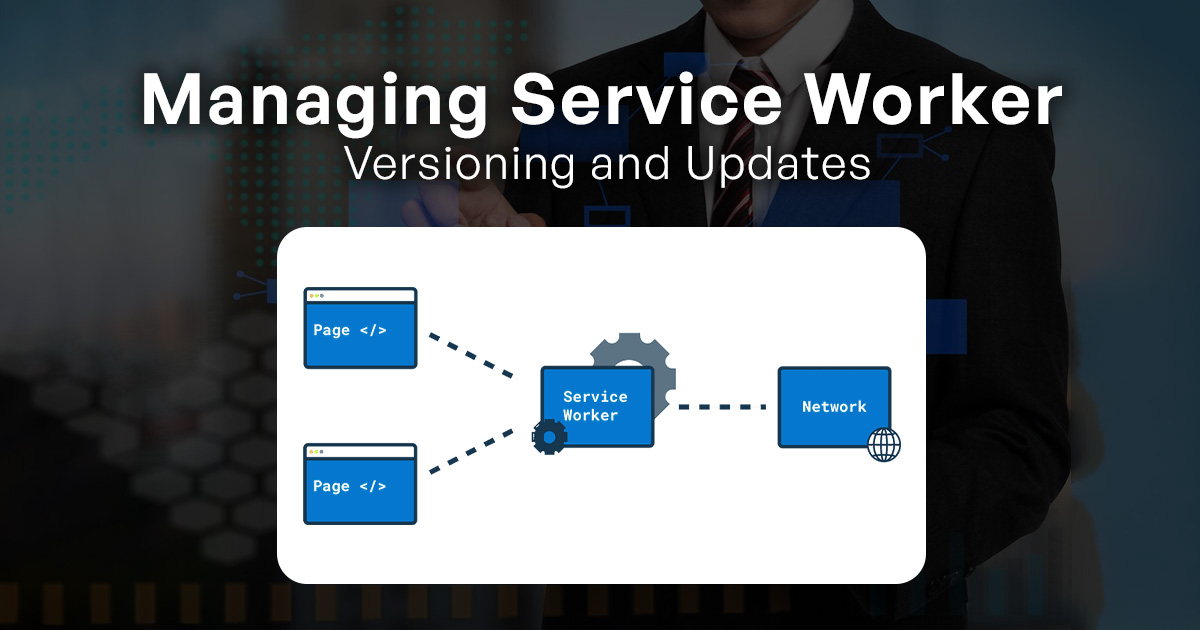
Why is version control important for service workers, and how does it impact updates?
Version control is crucial for service workers due to the distributed and cached nature of these scripts. Service workers are responsible for managing network requests, caching, and controlling access to web resources. When updates are required, having version control ensures a systematic approach to changes. Each version of a service worker is associated with specific functionality, bug fixes, or optimizations.
Impact on updates:
- Caching Consistency: Multiple clients (browsers) might have different versions of a service worker cached. Version control allows browsers to know which version to fetch and update, ensuring consistent behavior across users.
- Incremental Improvements: By tracking versions, developers can iteratively improve service worker behavior, addressing bugs or enhancing performance over time.
- Rollback Possibility: In case an update introduces unforeseen issues, version control enables developers to revert to a previously working version quickly.
What is the process for rolling out updates to a service worker while maintaining compatibility?
- Version Bumping: Increment the version number in the service worker’s code. This can be a part of the code comments or a dedicated constant.
- Update Strategy: Choose an update strategy, such as “Cache and Update” or “Network First.” This influences how the service worker responds to network requests during an update.
- New Precaching: Update the list of files to be precached. Include updated resources and remove obsolete ones.
- Activation Control: Inside the service worker code, handle the activation process. This can involve cleaning up old caches, ensuring that only the latest version is active.
- Registration and Update Logic: In your web app code, register the service worker with the updated version. Use the navigator.serviceWorker.register() method. When a new version is detected, it will trigger the installation process.
- Update Handling: Implement the serviceWorker.onupdatefound event to listen for updates. Once an update is found, it enters the “installing” phase, allowing you to manage the process.
How do you handle migrations when updating a service worker with significant changes?
Migrating a service worker with significant changes requires careful planning to ensure a seamless transition:
- Communication: Notify users in advance about the upcoming changes and potential service disruptions.
- Graceful Transition: Gradually introduce changes in a phased manner. This can involve deploying the new service worker to a small subset of users and gradually increasing the scope.
- Feature Flags: Implement feature flags or toggles that allow you to control the activation of new functionality independently of the service worker version.
- Testing Environment: Set up a testing environment to simulate the impact of changes before applying them to the production environment.
- Backward Compatibility: If possible, maintain backward compatibility with the previous version to ensure existing users don’t experience disruptions during the migration process.
How can you manage situations where multiple versions of a service worker are active?
Managing multiple versions of a service worker can be complex but is essential for a smooth user experience during updates:
- Versioned Caching: Each version of the service worker should cache resources with version-specific keys. This prevents conflicts between different versions.
- Activation Logic: Implement logic in the service worker to control which version becomes active. Newer versions can wait until previous versions are no longer in use before activating.
- Claim Clients: Use the serviceWorker.clients.claim() method to ensure that the active service worker immediately takes control of open client pages.
- Clearing Old Caches: During activation, remove outdated caches associated with previous versions to free up storage space.
- Communication: Inform users about the update process, encouraging them to reload the page to ensure they’re using the latest version.
- Testing: Thoroughly test scenarios where multiple versions might coexist, ensuring proper activation and cache management.
Progressive Enhancement and Resource Management
What is the concept of progressive enhancement, and how does it apply to offline mode?
Progressive enhancement is a design philosophy that advocates building web applications in layers, ensuring that the core functionality is available to all users regardless of their device or network capabilities. It involves starting with a baseline experience that works on all devices and browsers, and then adding advanced features for those with more capable environments.
When applied to offline mode in Progressive Web Apps (PWAs), progressive enhancement means providing a basic level of functionality even when the user is offline. This can be achieved by caching essential assets and data during the service worker installation process. As a result, users can still access certain parts of the application, view cached content, and perform basic tasks even when their internet connection is unreliable or unavailable.
How can progressive loading and lazy loading of resources enhance the user experience in PWAs?
Progressive loading and lazy loading improve user experience in PWAs by optimizing the loading process of resources:
- Progressive Loading: This approach involves prioritizing the loading of critical resources, such as HTML, CSS, and minimal JavaScript, first. As users interact with the PWA, additional resources are loaded progressively in the background. This ensures faster initial load times and a smoother user experience.
- Lazy Loading: Lazy loading involves loading resources only when they are needed. For instance, images below the fold of a webpage can be loaded as the user scrolls down. This conserves bandwidth and reduces initial page load time. Lazy loading is especially useful in PWAs where users might navigate through various sections without needing to load all resources upfront.
What strategies are available for prioritizing and prefetching resources in a PWA?
- Critical Rendering Path Optimization: Prioritize loading critical resources for rendering, like the main HTML, CSS, and initial JavaScript needed for above-the-fold content. This ensures that users can see and interact with content quickly.
- Prefetching: Use the <link rel=”prefetch”> attribute to hint to the browser that certain resources are likely to be needed in the near future. This helps in fetching and caching resources before they are explicitly requested.
- Data Prefetching: Anticipate user actions and prefetch data needed for those interactions. For example, prefetching data for the next page a user is likely to visit can reduce perceived load times.
- Service Worker Caching: Leverage the service worker to cache essential resources during installation, enabling the PWA to work offline or on low-quality networks.
Can you provide examples of scenarios where resource prioritization is critical for performance?
- Above-the-Fold Content: Loading resources required for content visible without scrolling is crucial for providing an initial rendering that users can engage with promptly.
- First Interactive Time: Resources necessary for enabling user interactions, like buttons or forms, should be prioritized to achieve a faster first interactive experience.
- Mobile Devices: Mobile devices often have limited bandwidth and processing power. Prioritizing essential resources helps ensure a smoother experience for mobile users.
- Image-heavy Pages: When dealing with pages with many images, lazy loading images below the fold can prevent unnecessary loading delays and reduce the initial data transfer.
- Transactional Actions: For PWAs involving transactions, prioritizing resources needed for completing transactions ensures a smooth process, reducing the chances of user frustration due to slow performance.
- Multi-Step Workflows: When users go through multi-step processes like signing up or making a purchase, preloading resources required for the next steps reduces waiting time between interactions.
Debugging and Troubleshooting
What tools are available for logging sync events and analyzing the performance of service workers?
Several tools can help with logging sync events and analyzing service worker performance:
- Chrome DevTools: The Application panel in Chrome DevTools provides insights into service workers. It allows you to monitor background sync events, view cached resources, and analyze the performance of service worker-related processes.
- Workbox DevTools: If you’re using the Workbox library for service workers, Workbox offers a set of DevTools extensions that provide detailed information about caching, routing, and background sync events.
- Lighthouse: Lighthouse, available in Chrome DevTools and as a standalone tool, can audit your PWA’s performance, including service worker-related aspects, and provide suggestions for improvement.
- Service Worker Cookbook: This resource provides examples of different service worker use cases, including logging techniques for debugging sync events.
How can you effectively debug background processes within a PWA?
Debugging background processes in PWAs, including service workers, requires specialized techniques:
- Service Worker DevTools: Most modern browsers offer specialized DevTools for service workers. You can inspect service worker registration, see active versions, and monitor fetch and sync events.
- Debugging with Breakpoints: Set breakpoints in your service worker code using DevTools. This allows you to pause execution and inspect variables, helping you identify issues.
- Logging: Use console logging within the service worker to track the flow of execution and the values of variables. You can log messages to the DevTools console using console.log().
- Remote Debugging: Some browsers allow remote debugging of service workers running on different devices. This is helpful for debugging scenarios that can’t be easily replicated locally.
What techniques can be employed for simulating different sync scenarios during testing?
Testing different sync scenarios is essential for ensuring robust background sync functionality:
- Offline Mode: Temporarily disable your network connection to simulate scenarios where background sync needs to handle data synchronization when the device is offline.
- Delayed Sync: Introduce artificial delays in your service worker sync code to simulate scenarios where syncing takes longer than usual.
- Custom Sync Events: Design your application to trigger custom sync events for testing purposes. For example, create a button that explicitly triggers a sync event when clicked.
- Browser DevTools: Use browser DevTools to simulate different network conditions, such as slow 3G or offline mode, to observe how your service worker and background sync behave.
How do you troubleshoot issues related to background sync functionality?
Troubleshooting background sync issues can involve several steps:
- Check Service Worker Registration: Ensure your service worker is correctly registered and activated. Check for any errors in the console related to registration or activation.
- Logging: Add detailed logging to your service worker sync event handlers to track the flow of execution and identify any unexpected behaviors.
- Network Requests: Inspect network requests made during sync events to verify if data is being sent and received as expected.
- Offline Testing: Test your background sync logic in offline mode to see how it behaves when the device has no network connectivity.
- Browser DevTools: Use browser DevTools to monitor the background sync events, view any errors or warnings, and understand how the service worker behaves.
- Service Worker Lifecycle: Understand the service worker lifecycle and ensure that your sync event handlers are set up correctly to respond to sync events.
- Browser Compatibility: Check if the background sync feature is supported in the browser and version you are using. Different browsers might have variations in implementation.
- Third-Party Libraries: If you’re using libraries like Workbox, ensure they are configured correctly and are not causing conflicts with your sync logic.
Implementing UI and UX with Background Sync
How can background sync processes be integrated with the user interface (UI) of a PWA?
Integrating background sync processes with the UI of a PWA involves providing user feedback and control:
- User Awareness: Inform users about the background sync feature, explaining its benefits and how it enhances their experience.
- Sync Status Display: Display a status indicator, such as an icon or text, to show when background sync is active or when data has been successfully synced.
- Sync Control: Offer users the ability to initiate manual syncs in addition to automatic ones. This could be through a button or menu option.
- Notifications: Notify users when syncs are successful or when issues arise during the background sync process.
- Offline Mode Handling: Design your UI to gracefully handle situations when a user initiates an action that requires sync while offline.
What are some best practices for providing visual indicators, such as progress bars, during sync?
Visual indicators enhance the user experience by providing feedback on ongoing background sync processes:
- Progress Bars: Use progress bars to indicate the status of sync operations. Progress bars help users understand that something is happening and how long it might take.
- Animated Icons: Utilize animated icons or loaders to visually signal activity. This gives users a sense of action even if they don’t see a concrete progress value.
- Transparency: Make sure your indicators accurately reflect the progress of the sync process. Avoid overestimating progress or providing misleading information.
- Minimal Intrusion: Keep indicators unobtrusive so that they don’t distract from the main content. They should provide valuable information without disrupting the user’s focus.
- Responsive Design: Ensure that your indicators work well on different screen sizes and devices. They should be visible and effective across various platforms.
How do you handle interruptions and errors in the background sync process while maintaining UI/UX?
Dealing with interruptions and errors gracefully is crucial for maintaining a positive user experience:
- User-Friendly Errors: When errors occur, display user-friendly messages that explain what went wrong and provide guidance on how to resolve the issue.
- Retry Mechanisms: Offer users the option to retry failed syncs. This can be through a “Retry” button or an automatic retry mechanism after a certain time interval.
- Error Logging: Log errors on the client and server sides for diagnostics. Use this information to identify and fix recurring issues.
- Offline Handling: Design your PWA to handle situations where the sync process is interrupted due to loss of network connectivity. Store pending actions and attempt sync when the connection is restored.
- Fallback Data: In cases where a sync fails to update data, ensure that your PWA uses cached or locally available data to maintain functionality for the user.
- User Guidance: Provide clear instructions on what users should do in case of recurring errors or interruptions. This could involve checking their internet connection or contacting support.
Strategies for Data Synchronization and Conflict Resolution
What are the different modes and frequencies of offline data synchronization?
Offline data synchronization can be approached in various modes and frequencies:
- Manual Sync: Users trigger synchronization explicitly, such as clicking a “Sync” button.
- Scheduled Sync: Automate synchronization on a predefined schedule, like hourly or daily.
- Background Sync: Leverage the background sync API to synchronize data when network connectivity is available, even if the app is not open.
- On-Demand Sync: Synchronize data when specific events occur, such as new data creation or updates.
- Hybrid Approach: Combine multiple modes for flexibility. For example, allow manual sync but also perform periodic background syncs for essential data.
What queueing strategies can be employed to manage data synchronization tasks?
Queueing strategies ensure data synchronization tasks are managed effectively:
- FIFO (First-In-First-Out): Process tasks in the order they were added to the queue. Simple and ensures fairness.
- Priority Queue: Assign different priority levels to tasks, allowing higher-priority tasks to be processed before others.
- Throttling: Limit the rate at which tasks are processed to avoid overloading the system or network.
- Retrying: Implement retry mechanisms for failed tasks, with increasing time intervals between retries.
- Batching: Combine multiple smaller tasks into larger batches for efficiency.
- De-duplication: Avoid duplicating similar tasks to optimize resource usage.
How do you handle conflicts during data synchronization, and what are common resolution methods?
Conflicts can arise when data is modified both locally and remotely. Strategies for conflict resolution include:
- Timestamp or Version: Attach timestamps or version numbers to records. When syncing, compare timestamps or versions to determine which version is newer.
- Last Writer Wins: When conflicts occur, use the version modified most recently as the valid version.
- User Interaction: Notify users of conflicts and let them manually decide which version to keep.
- Merge: For certain data types, implement merge strategies that combine conflicting changes intelligently.
- Automatic Resolution Rules: Define predefined rules for specific fields to resolve conflicts, based on priority or other criteria.
- Audit Trail: Keep a history of changes to assist in conflict resolution.
Can you provide examples of scenarios where concurrent modification handling is crucial?
Concurrent modification handling is essential in scenarios where multiple users or devices can modify the same data simultaneously:
- Collaborative Document Editing: In applications like Google Docs, multiple users can edit a document simultaneously. Handling concurrent modifications ensures that all changes are captured accurately.
- Inventory Management: In retail systems, inventory levels need to be accurate even when multiple users update stock levels concurrently.
- Messaging Apps: In chat applications, users might send messages concurrently, and it’s crucial to maintain the conversation flow and message order.
- E-commerce Carts: When multiple users are adding items to their carts simultaneously, proper handling is needed to prevent overselling or data loss.
- Calendar Apps: In shared calendars, users scheduling events concurrently should not result in overlapping or missing events.
SSL Certificates and HTTPS Implementation
How is HTTPS implemented in PWAs, and why is it important for secure communication?
HTTPS (Hypertext Transfer Protocol Secure) is implemented in PWAs through SSL/TLS encryption, which encrypts data exchanged between the user’s browser and the web server. This encryption ensures that data, including sensitive user information, remains confidential and cannot be easily intercepted or manipulated by attackers.
Importance of HTTPS in PWAs:
- Data Privacy: HTTPS protects user data, preventing unauthorized access and eavesdropping during communication.
- Authentication: It verifies the identity of the server, ensuring users are interacting with the genuine application.
- Integrity: HTTPS ensures that data sent or received has not been altered or tampered with during transit.
- Trustworthiness: Browsers indicate secure connections with a padlock icon, building user trust in the PWA.
- Service Worker Security: Without HTTPS, service workers and background sync might be vulnerable to attacks like man-in-the-middle.
What is the role of SSL certificates in establishing a secure connection for background sync?
SSL certificates play a critical role in establishing a secure connection for background sync by ensuring the authenticity of the server and enabling encrypted communication. They provide the following benefits:
- Server Authentication: SSL certificates verify that the server is genuine and not impersonated, preventing man-in-the-middle attacks.
- Data Encryption: Certificates enable encryption of data transmitted during background sync, safeguarding it from interception.
- Trust Indicators: SSL certificates trigger trust indicators like the padlock icon, assuring users of a secure connection.
- Certificate Transparency: It enhances security by publicly logging issued certificates, which can help detect unauthorized certificate issuance.
How can content security policies (CSPs) contribute to security within PWAs?
Content Security Policies (CSPs) are security mechanisms that mitigate various types of attacks, including cross-site scripting (XSS) and data injection:
- XSS Mitigation: CSPs prevent the execution of malicious scripts by specifying which sources of scripts are allowed to run.
- Data Injection Prevention: CSPs restrict unauthorized data injection by controlling which domains are allowed to receive and send data.
- Mitigating Code Injection: CSPs reduce the risk of code injection attacks by defining allowed script sources.
- Resource Loading Control: CSPs limit loading of external resources like images and fonts to trusted sources, preventing resource hijacking.
What considerations are essential when implementing HTTPS in background processes?
Implementing HTTPS in background processes requires careful planning:
- Service Worker Scope: Ensure your service worker’s scope matches the HTTPS domain, as service workers can only control pages within their scope.
- Mixed Content: Avoid mixed content (HTTP resources on HTTPS pages), as it can lead to security warnings and pose a risk to the PWA’s security.
- Security Headers: Implement security headers like Strict Transport Security (HSTS) to enforce HTTPS usage and prevent downgrade attacks.
- CORS Configuration: Set up Cross-Origin Resource Sharing (CORS) policies to control which domains can access your PWA’s resources.
- Certificate Validity: Keep SSL certificates up-to-date to prevent service disruption due to expired certificates.
- Background Sync Endpoint: If your background sync uses an API endpoint, ensure it is also served over HTTPS.
- Testing and Monitoring: Regularly test and monitor background sync functionality to identify security vulnerabilities and ensure proper operation.
Using Device APIs in PWAs
What are native device features, and how can they be integrated into PWAs?
Native device features refer to functionalities available on a user’s device, such as camera, geolocation, sensors, notifications, and more. These features can be integrated into Progressive Web Apps (PWAs) using JavaScript APIs and standards provided by modern web browsers. This allows PWAs to leverage device capabilities just like native mobile apps.
How do you access the camera and geolocation APIs within a PWA?
To access the camera and geolocation APIs within a PWA:
- Camera API:
- Use the getUserMedia() method with the video constraint to access the camera stream.
- Display the camera stream in a <video> element.
- You can capture images from the stream and manipulate them.
- Geolocation API:
- Use the navigator.geolocation object to access the geolocation API.
- Call the getCurrentPosition() method to retrieve the current user’s position.
- You can also watch for continuous position updates using the watchPosition() method.
Can you provide examples of use cases where native device features enhance PWA functionality?
- Camera Access for Scanning: Use the camera API to enable barcode or QR code scanning within the PWA for inventory management or product recognition.
- Geolocation-Based Services: Utilize the geolocation API to offer location-based services like finding nearby stores, services, or events.
- Device Orientation: Use device orientation APIs to create interactive experiences that respond to the user’s device orientation, such as 360-degree image viewers.
- Push Notifications: Implement push notifications to keep users informed of important updates even when the PWA isn’t open.
- Offline Data Collection: Leverage device features to capture and store data offline, like field surveys or inspection reports.
What strategies are available for ensuring a consistent experience across different devices?
Ensuring a consistent experience across different devices in PWAs requires careful consideration:
- Responsive Design: Design your PWA with responsive layouts that adapt to different screen sizes and orientations.
- Feature Detection: Use feature detection to determine if a specific device capability is available before attempting to use it. This prevents errors on unsupported devices.
- Progressive Enhancement: Start with a core experience that works on all devices, then enhance it with device-specific features.
- Media Queries: Utilize media queries in your CSS to apply different styles based on the screen size and other device characteristics.
- Testing and Debugging: Regularly test your PWA on various devices and browsers to identify and fix any inconsistencies or issues.
- Fallbacks and Polyfills: Provide fallbacks or use polyfills for devices that lack certain features or support.
- User Feedback: Collect user feedback to identify devices or scenarios where the experience might not be consistent, and make improvements accordingly.
Accessibility Considerations in PWAs
How can accessibility be ensured when developing PWAs?
Ensuring accessibility in PWAs requires following best practices and considering the needs of users with disabilities:
- Semantic HTML: Use proper HTML elements for their intended purposes to ensure screen readers and assistive technologies can interpret content correctly.
- Keyboard Navigation: Ensure all interactive elements can be navigated and activated using keyboard inputs alone.
- ARIA Roles and Attributes: Use ARIA (Accessible Rich Internet Applications) roles and attributes to enhance the accessibility of dynamic content and custom components.
- Color Contrast: Maintain sufficient color contrast between text and background to make content readable for users with visual impairments.
- Alternative Text: Provide meaningful alternative text for images and other non-text content.
- Focus Styles: Clearly indicate focus states for interactive elements, allowing keyboard users to understand where they are in the interface.
- Content Structure: Use appropriate headings, lists, and semantic structure to organize content logically.
- Testing with Screen Readers: Regularly test your PWA using screen readers and assistive technologies to identify and fix accessibility issues.
What are the key techniques for building inclusive web experiences in the context of PWAs?
Key techniques for building inclusive web experiences in PWAs include:
- Keyboard Accessibility: Ensure all features and interactions can be accessed and used using keyboard navigation alone.
- Screen Reader Compatibility: Use semantic HTML and ARIA attributes to ensure compatibility with screen readers.
- Text Alternatives: Provide text alternatives for images, videos, and other non-text content.
- Responsive Design: Design your PWA to be usable across different screen sizes and orientations.
- Focus Indicators: Make sure interactive elements have clear and visible focus indicators.
- Audio and Video Accessibility: Provide captions for videos and ensure audio content has transcripts.
How do accessibility guidelines apply to background sync and push notification features?
For background sync and push notification features, accessibility guidelines apply as follows:
- Background Sync:
- Ensure that background sync tasks don’t disrupt the user experience or cause unexpected behavior.
- Provide clear feedback or notifications when background sync tasks complete or encounter errors.
- Push Notifications:
- Allow users to control push notifications by providing clear opt-in and opt-out options.
- Ensure that the content of push notifications is concise, relevant, and accessible.
Can you provide examples of scenarios where accessibility enhancements are crucial for PWAs?
- E-commerce PWAs: Ensuring that users with disabilities can easily browse products, add items to carts, and complete purchases is crucial for inclusive shopping experiences.
- News and Content Apps: Making news articles, videos, and multimedia content accessible ensures that users with various disabilities can access and engage with the content.
- Educational PWAs: Educational PWAs should be designed to accommodate diverse learning styles and needs, providing accessible resources and interactive elements.
- Collaborative Apps: Apps that involve collaboration and data sharing need to ensure that users with disabilities can effectively contribute and interact with the content.
- Booking and Reservation Systems: Making sure users with disabilities can easily book services, make reservations, and manage appointments is essential for accessibility.
SEO Optimization for PWAs
How can PWAs be optimized for search engine visibility?
Optimizing PWAs for search engine visibility requires a combination of traditional SEO techniques and considerations specific to PWAs:
- Crawlable Content: Ensure that essential content is accessible to search engines by avoiding JavaScript-based rendering and using semantic HTML.
- Metadata: Optimize meta titles, descriptions, and other meta tags to accurately describe your PWA’s content.
- Structured Data: Implement structured data markup (Schema.org) to help search engines understand the context of your content.
- Responsive Design: Create a responsive design that adapts to different devices and screen sizes.
- Page Speed: Optimize loading times to improve user experience and search engine rankings.
- XML Sitemap: Create an XML sitemap to guide search engines in discovering and indexing your PWA’s pages.
Q2: What are the best practices for implementing progressive web app SEO strategies?
Progressive Web App SEO strategies combine traditional SEO practices with PWA-specific considerations:
- Server-Side Rendering (SSR): Implement SSR to ensure that search engines can crawl content that is rendered dynamically on the client side.
- Unique URLs: Use unique URLs for different sections of your PWA to enable better indexing of individual pages.
- Hreflang Tags: Use hreflang tags to indicate different language or regional versions of your PWA’s content.
- Canonical URLs: Use canonical tags to indicate the preferred version of duplicate content.
- Optimized Images: Compress and optimize images to improve page load times.
- Structured Data: Implement structured data for enhanced search engine result snippets.
Q3: How do background sync, push notifications, and data pre-caching impact SEO efforts?
- Background Sync: Background sync improves user experience by allowing data synchronization even when the PWA isn’t open. While it doesn’t have a direct impact on SEO rankings, it enhances user engagement, which indirectly contributes to positive SEO signals.
- Push Notifications: Push notifications can improve user engagement and retention, leading to longer visit durations and more frequent visits. These factors can indirectly contribute to better SEO rankings.
- Data Pre-caching: Pre-caching resources can improve page load times, which is a ranking factor for SEO. Faster loading enhances user experience, reducing bounce rates and improving engagement.
Can you provide examples of successful PWAs that have effectively utilized SEO strategies?
- Pinterest: Pinterest’s PWA effectively utilizes SEO strategies, leading to better discoverability of pins and boards by search engines.
- Forbes: Forbes’ PWA has seen success by combining fast load times, engaging content, and optimized metadata for better search engine visibility.
- Twitter Lite: Twitter’s PWA, Twitter Lite, uses progressive enhancement techniques and optimized metadata to enhance its SEO performance.
Implementing Cross-Browser Compatibility
How can you ensure cross-browser compatibility when implementing advanced service worker techniques?
Ensuring cross-browser compatibility for advanced service worker techniques involves several steps:
- Feature Detection: Use feature detection libraries or native checks to determine if a specific service worker feature is supported by the browser.
- Polyfills: Use polyfills or libraries like Workbox to provide consistent behavior across browsers that might have varying levels of support.
- Progressive Enhancement: Start with a baseline service worker functionality that works on all browsers and progressively enhance it with features supported by specific browsers.
- Testing on Multiple Browsers: Regularly test your advanced service worker techniques on different browsers to identify issues and inconsistencies.
Q2: What strategies can be employed to handle variations in service worker support across browsers?
To handle variations in service worker support:
- Graceful Degradation: Design your PWA to function properly even if advanced service worker features are not supported.
- Conditional Loading: Load specific service worker code based on feature support. This ensures that only compatible browsers execute advanced techniques.
- Feature Detection: Use feature detection to check if specific APIs or methods are available before attempting to use them.
- Polyfills: Utilize polyfills to mimic unsupported service worker functionality in browsers lacking native support.
Q3: How do different browser engines interpret and execute background sync, push notifications, and caching strategies?
Different browser engines (like Blink in Chrome, Gecko in Firefox, WebKit in Safari, etc.) might have variations in how they interpret and execute service worker features:
- Background Sync: While the core concept is consistent, browser engines might have different implementations for managing and triggering background sync events.
- Push Notifications: The process of registering for and handling push notifications might vary due to differences in browser APIs and backend server requirements.
- Caching Strategies: Caching strategies like cache-first, network-first, and others should work similarly across browsers, but there might be subtle differences in cache storage and retrieval behaviours.
It’s important to test your service worker-based features across different browsers to identify and address any compatibility issues arising from variations in browser engines.
Measuring Performance Impact
What methods can you use to measure the performance impact of advanced service worker techniques?
Measuring the performance impact of advanced service worker techniques involves various methods:
- Browser DevTools: Use browser developer tools to analyze network activity, performance timelines, and resource caching.
- Lighthouse Audits: Lighthouse, available in DevTools and as a standalone tool, provides performance audits for PWAs, including service worker-related metrics.
- Performance APIs: Utilize the Navigation Timing API and User Timing API to collect detailed performance data.
- Real User Monitoring (RUM): Implement RUM tools to track how real users experience your PWA’s performance.
- Load Testing: Conduct load tests to simulate heavy traffic and evaluate how service worker techniques impact server load and responsiveness.
Q2: How do background sync, push notifications, and data pre-caching affect a PWA’s loading speed and responsiveness?
- Background Sync: Background sync doesn’t directly impact initial loading speed, but it enhances responsiveness by allowing data updates even when the user isn’t actively interacting with the PWA.
- Push Notifications: While push notifications themselves don’t affect loading speed, they can impact responsiveness if not implemented efficiently. If a push notification triggers a resource-heavy action when clicked, it might affect the PWA’s responsiveness.
- Data Pre-caching: Properly implemented data pre-caching can improve loading speed by ensuring essential resources are already cached when the PWA is accessed, leading to quicker page loads.
Q3: What metrics should developers track to assess the success of these techniques?
- Time to First Byte (TTFB): Measure how quickly the server responds after a request is made. A lower TTFB indicates better server performance.
- First Contentful Paint (FCP): This metric measures when the first content starts rendering on the screen. A quick FCP enhances perceived speed.
- First Meaningful Paint (FMP): FMP measures when meaningful content appears, providing a better indication of user experience.
- Time to Interactive (TTI): TTI measures when a page becomes interactive, indicating when users can start interacting with the content.
- Background Sync Success Rate: Track the success rate of background sync tasks. A higher success rate indicates robust data synchronization.
- Push Notification Engagement: Monitor how users interact with push notifications, such as click-through rates and conversion rates.
- Data Pre-caching Efficiency: Evaluate how well pre-cached data improves subsequent page loads and user interactions.
- Resource Utilization: Assess server load and resource usage to ensure that advanced techniques don’t negatively impact performance under heavy traffic.
Privacy Considerations in Push Notifications
What are the privacy implications of implementing push notifications in PWAs?
Implementing push notifications in PWAs involves several privacy considerations:
- User Consent: Users need to provide explicit consent before receiving push notifications. Failing to obtain consent could result in privacy violations.
- User Data: Push notifications can reveal user behavior and interests. Improper use or sharing of this data can infringe upon user privacy.
- Tracking: Some push notification services track user activity for analytics. Transparency about data collection and usage is crucial.
- Personalization: Personalizing notifications based on user data requires careful handling to avoid crossing privacy boundaries.
Q2: How can user consent and permissions be managed for push notification functionality?
To manage user consent and permissions effectively:
- Opt-In Mechanism: Present a clear opt-in mechanism for push notifications during the PWA’s onboarding process.
- Explanation: Provide a concise and transparent explanation of why users should enable push notifications and what benefits they can expect.
- Granular Control: Allow users to customize which types of notifications they want to receive and how often.
- Opt-Out: Include an easy-to-find opt-out option for users who change their minds or want to stop receiving notifications.
- User Profiles: Allow users to manage their notification preferences within their user profiles.
Q3: What measures can be taken to protect user data and ensure compliance with privacy regulations?
To protect user data and comply with privacy regulations:
- Data Minimization: Collect only the data necessary for delivering push notifications. Avoid unnecessary user profiling.
- Encryption: Ensure that user data, including push notification tokens, is encrypted both during transmission and storage.
- Third-Party Services: If using third-party push notification services, choose providers that prioritize data security and comply with privacy regulations.
- Data Retention: Establish clear policies for how long user data, including notification history, will be retained.
- Privacy Policy: Maintain a comprehensive privacy policy that informs users about how their data is collected, used, and protected.
- Compliance Audits: Regularly review and update your push notification practices to ensure continued compliance with evolving privacy regulations.
- User Rights: Respect user rights under regulations such as GDPR, including the right to access, correct, and delete their data.
- Transparency: Provide users with clear information about how their data is used for push notifications, and allow them to opt out if desired.
Managing Background Sync on Slow Networks
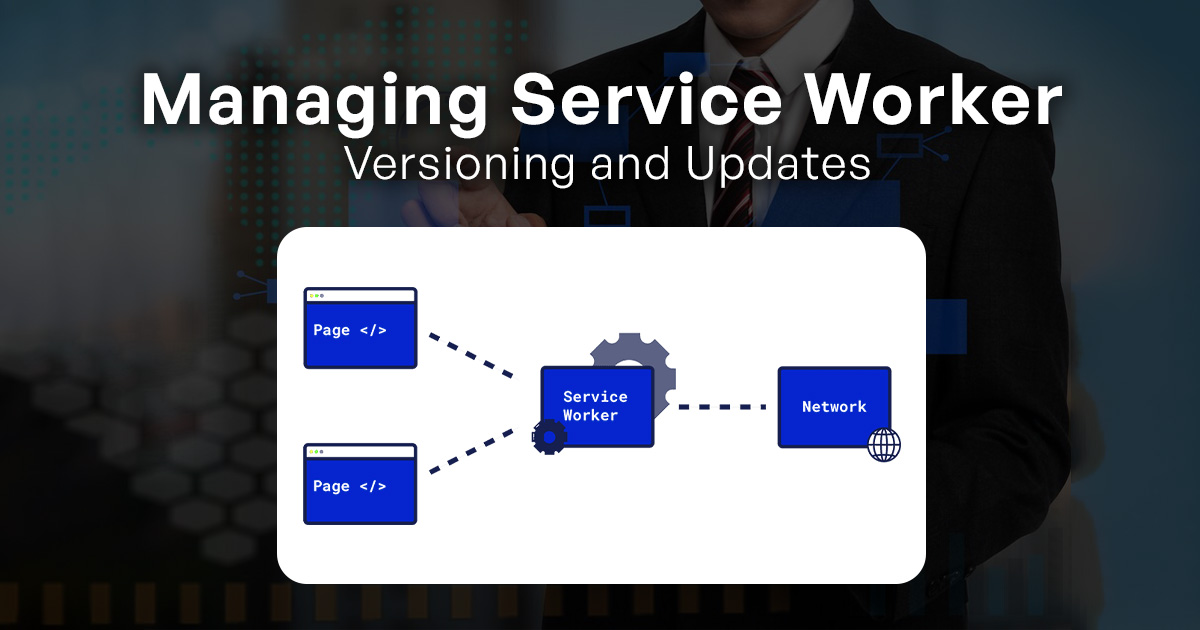
How can background sync processes be optimized for users on slow or unreliable networks?
Optimizing background sync for users on slow or unreliable networks requires a user-centric approach:
- Throttling: Implement sync throttling to limit the frequency of sync attempts on slow networks, preventing excessive data usage.
- Adaptive Sync: Implement logic to adjust the amount of data synced based on network conditions. Prioritize critical data over non-essential updates.
- Progressive Loading: Divide sync tasks into smaller chunks, allowing users on slow networks to receive updates gradually.
- Data Compression: Compress data before syncing to reduce the amount of data transferred over slow networks.
What strategies can be employed to prevent sync-related disruptions on low-bandwidth connections?
To prevent disruptions during sync on low-bandwidth connections:
- Prioritization: Prioritize essential data and tasks for synchronization, ensuring critical updates are delivered first.
- Offline Queuing: Queue sync tasks when the network is slow or unavailable, and process them once the connection improves.
- Retry Mechanisms: Implement intelligent retry mechanisms that adapt to network conditions. Increase retry intervals on slow networks.
- Batching: Group multiple small sync tasks into larger batches to minimize the impact of individual requests on network resources.
How do you balance the need for timely sync with minimizing the impact on limited network resources?
Balancing timely sync with limited network resources requires a careful approach:
- User Control: Allow users to control when and how often background sync occurs. Provide settings to enable manual triggering.
- Scheduled Sync: Implement scheduled sync based on user behavior or predictable network availability.
- Opt-Out Option: Allow users to opt out of background sync if they are concerned about data usage.
- Efficient Data Usage: Optimize data usage by sending only necessary updates and compressing data before syncing.
- Feedback Mechanism: Provide users with feedback on when sync tasks are completed successfully, helping them understand the impact on network resources.
Handling Data Integrity and Rollbacks
How can data integrity be maintained when performing transactions with IndexedDB in offline mode?
Maintaining data integrity in IndexedDB during offline transactions involves careful handling:
- Validation: Validate data before performing transactions to ensure that it meets required constraints and won’t lead to inconsistencies.
- Transaction Scopes: Wrap operations in transactions to ensure that either all changes are applied, or none at all. This prevents partial changes in case of failures.
- Rollback Handling: Implement rollback mechanisms that restore the database to a consistent state if a transaction fails.
- Caching Strategies: Use caching strategies to ensure that data fetched from IndexedDB during offline mode remains up-to-date and consistent.
What strategies are available for implementing rollbacks in case of transaction failures?
Implementing rollbacks in case of transaction failures involves a combination of techniques:
- Savepoints: Use savepoints or checkpoints to mark a consistent state before starting a transaction. If the transaction fails, you can roll back to the savepoint.
- Transaction Reversal: After a failure, execute a transaction that reverses the changes made by the failed transaction, restoring the database to its original state.
- Compensating Transactions: Design compensating transactions that undo the effects of a failed transaction by applying reverse changes.
- Error Handling: Implement thorough error handling mechanisms to detect transaction failures and trigger rollback procedures.
Can you provide examples of scenarios where data integrity and rollbacks are critical considerations?
- Financial Transactions: In a banking application, if a user initiates a fund transfer while offline and the transaction fails due to network issues, maintaining data integrity is crucial. Rollbacks ensure that the user’s balance is not affected incorrectly.
- E-commerce Orders: In an online store PWA, if a customer places an order offline and the transaction fails, proper rollbacks prevent the creation of erroneous orders.
- Inventory Management: In a retail inventory management system, offline stock updates need to be reversible to avoid discrepancies in stock levels.
- Collaborative Editing: In collaborative document editing PWAs, if offline changes conflict with concurrent online changes, data integrity and rollbacks help resolve conflicts without data loss.
- Reservation Systems: In booking applications, if a user reserves a spot offline but the transaction fails, rollbacks prevent double-bookings and maintain reservation accuracy.
Implementing Background Sync in Hybrid Apps
How can the principles of background sync be applied to hybrid mobile apps?
The principles of background sync can be applied to hybrid mobile apps by leveraging the capabilities of hybrid app development frameworks, such as Apache Cordova or React Native:
- Service Worker Equivalent: While hybrid apps don’t use service workers like PWAs, you can achieve similar functionality using background tasks provided by the hybrid framework.
- Background Jobs: Utilize background job scheduling mechanisms provided by the framework to trigger data synchronization or updates when the app is in the background.
- Offline Storage: Use local storage or databases provided by the hybrid framework to store data that needs to be synchronized during background sync.
- Retry and Throttling: Implement retry mechanisms and throttling logic to handle sync failures and manage data usage.
What are the considerations and challenges specific to integrating advanced service worker techniques in hybrid apps?
Integrating advanced service worker techniques in hybrid apps involves considerations and challenges unique to hybrid app development:
- Platform Limitations: Different hybrid frameworks have varying levels of support for background tasks and APIs. You need to work within the limitations of the chosen framework.
- Native Plugins: To achieve advanced functionality, you might need to develop or utilize native plugins that bridge the gap between hybrid apps and native device capabilities.
- Foreground Interruptions: Hybrid apps can be more susceptible to being paused or interrupted when moved to the background, affecting the timing and reliability of background tasks.
- Resource Usage: Managing resource usage (CPU, battery, memory) during background sync is crucial to avoid degrading the overall performance of the device.
- Testing Complexity: Testing advanced service worker techniques in hybrid apps requires thorough testing across different devices, operating systems, and scenarios.
- Synchronization Logic: Developing logic to synchronize data effectively and handle conflicts when the app resumes from the background is a challenge in hybrid apps.
- Consistency Across Platforms: Achieving consistent behaviour and user experience across different platforms can be complex due to the differences in how hybrid frameworks interact with native components.


